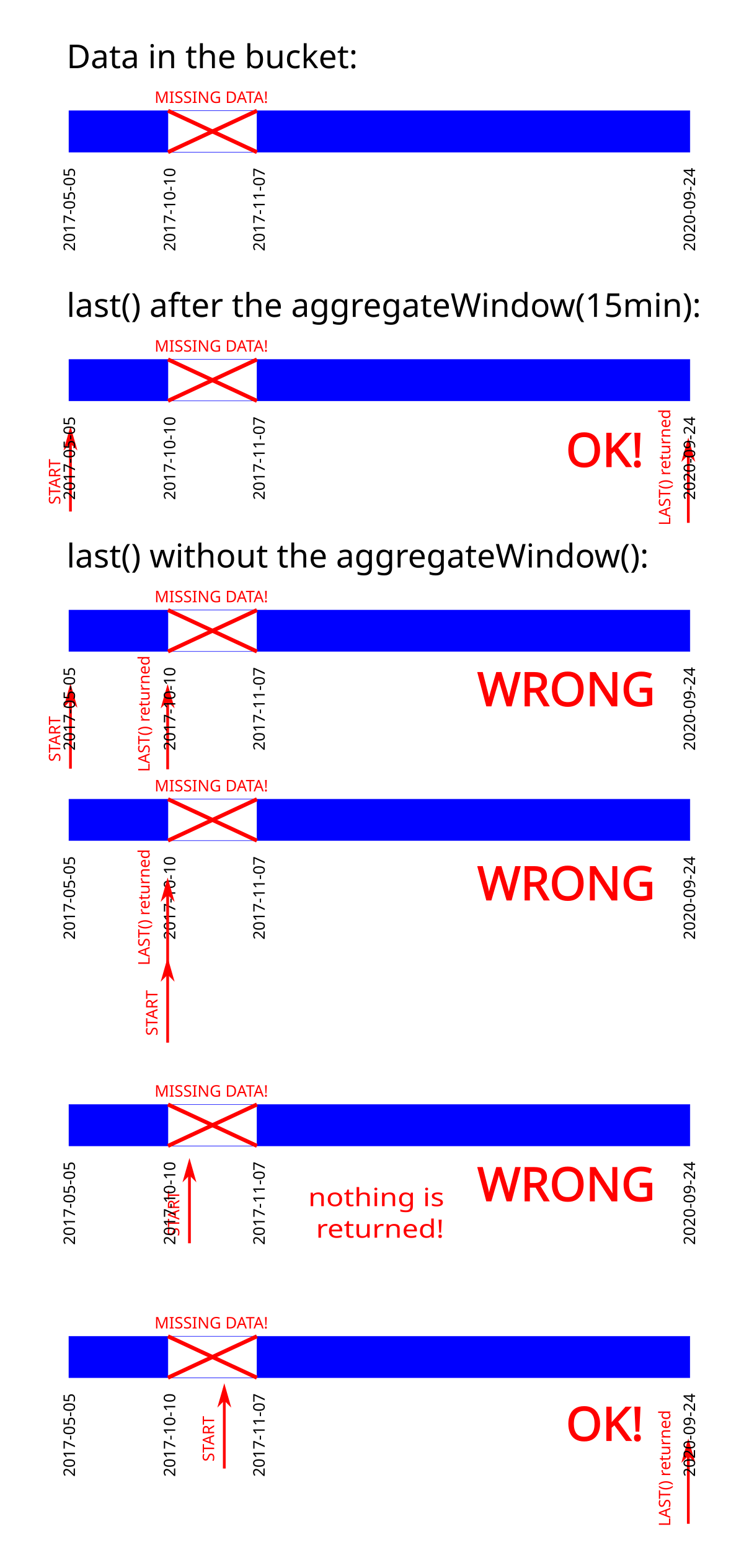
I need to extract the _time of the last record in a bucket.
The dataset goes from 2017-05-05... to 2020-09-24..., one row every 5 seconds.
There are missing data (no rows at all) from 2017-10-10... to 2017-11-07...
START = 0
from(bucket: BUCKET)
|> range(start: START, stop: now())
|> filter(fn: (r) => r["_measurement"] == MEASUREMENT and r["_field"] == FIELD)
|> aggregateWindow(every: 15m, fn: mean, createEmpty: false)
|> last(column: "_time")
|> yield(name: "mean")
returns 2020-09-24..., the correct answer.
START = 0
from(bucket: BUCKET)
|> range(start: START, stop: now())
|> filter(fn: (r) => r["_measurement"] == MEASUREMENT and r["_field"] == FIELD)
|> last(column: "_time")
|> yield(name: "mean")
(without the aggregateWindow returns a single 2017-10-10... instead.
It is the last record BEFORE the missing data span, not what I want.
Changing the START time only in the second script:
- START = 2017-10-10 => 2017-10-10T20:45:30Z (last value before the missing data span)
- START = 2017-10-11 => empty (it looks like it doesn’t like to start in the middle of the missing data span)
- START = 2017-10-16 => it returns the correct answer! (but we are in the middle of the missing data span yet)
Any reason why?