Thank you for the input, and you have nothing to be sorry about. I am grateful for your time.
Sadly, your suggestion just pushes the error back to the previous line:
Tried ChatGPT4 with this question and here is what it came up with. I have not had an opportunity to test it.
To use the timestamp obtained from one query as the start time value for another query’s range() function, you can use the join() function in InfluxDB. In this example, the timestamp_query gets the timestamp from the first query, and the second_query is defined as a function that takes the start time as a parameter. Then, the join() function is used to combine the timestamp from the first query with the second query, using the timestamp as the start time for the range() function.
// Replace these placeholders with your actual values
bucket_name = "TEMP_DATA"
measurement_name = "placeholder_1"
measurement_name_2 = "placeholder_2"
// Get the timestamp from the first query
timestamp_query = from(bucket: bucket_name)
|> range(start: -2m)
|> filter(fn: (r) => r._measurement == measurement_name)
|> group()
|> last()
|> keep(columns: ["_time"])
|> limit(n: 1)
|> map(fn: (r) => ({_time: r._time, key: "timestamp"}))
// Second query that will use the timestamp from the first query as the start time
second_query = (startTime) => from(bucket: bucket_name)
|> range(start: startTime)
|> filter(fn: (r) => r._measurement == measurement_name_2)
// Join the timestamp_query and second_query and use the timestamp as the start time
result = join(
tables: {timestamp: timestamp_query, data: second_query(timestamp_query[0]._time)},
on: ["_time"]
)
// Yield the result
result |> yield(name: "result")
thanks for looking into the problem again. I tried chatgpt as well, sadly got no helpful results.
Your’s was different and I tried it. Sadly, this is the result:
Brilliant suggestion @gazpachoking! You are correct in that one must get an individual record. @mauflege: There are probably several ways to do this, but in my sample dataset I got it to work using the Extract Scalar Value feature.
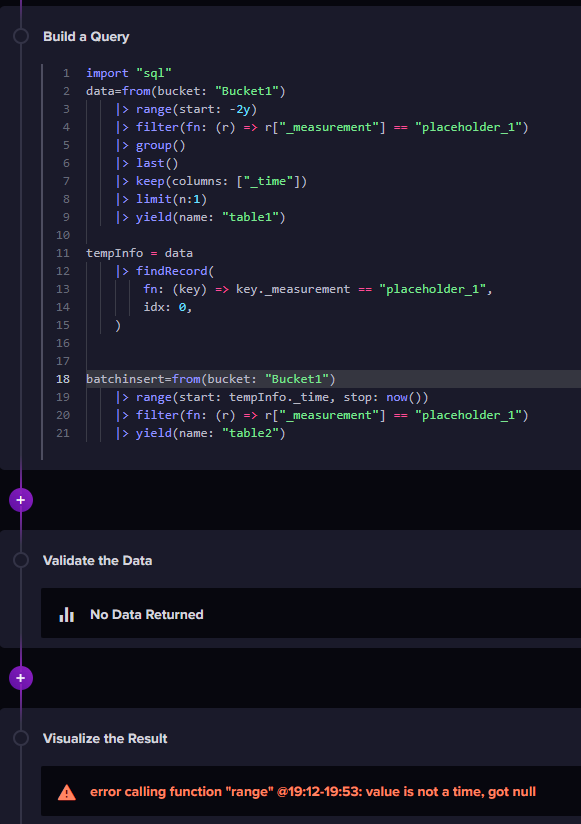
the query is returning a "null’ value, it says it error on line 19. tempInfo doesn’t have _time property because it is a “null” value.
change this line |> keep(columns: ["_time"]) // not sure this line is needed
for this |> keep(columns: ["_time","_measurement"]) // not sure this line is needed or just delete it entirely.
if you used |> keep(columns: ["_time"]) then there is no _measurement tag anymore, you dropped it! so, findRecord() is going to return a “null” value. because there isn’t any record with tag named _meassurement!
tempInfo is returning a null value, the fact that you can see the result of the first table does not mean that findRecord() is finding a record. delete |> group () or use except by time.
I cannot explain quite well why, but its like _time is reserved to be used as a group column, if you ungroup using group() then there won’t be finding a “_time” column and the result will be null.
probably renaming or duplicating the column _time to another before doing the findRecord, and then referencing the new name may work too.
@fercasjr Thanks so much, that did it. Got it working. @grant1 Thank you for your patience in looking for a solution and helping me out. @gazpachoking Thank you for providing the initial push towards a solution!