hi,
i configured telegraf to parse some files with grok. it works fine, but when the files are encoded in utf16-le-bom i am not able to parse them:
2021-10-04T16:10:06Z I! Starting Telegraf 1.19.2
2021-10-04T16:10:06Z D! [agent] Initializing plugins
2021-10-04T16:10:06Z D! [agent] Starting service inputs
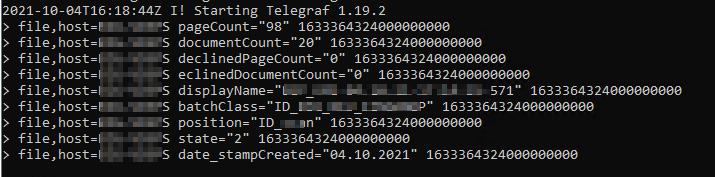
2021-10-04T16:10:06Z D! Grok no match found for: "T\x00B\x00a\x00t\x00c\x00h\x00 \x00B\x00a\x00t\x00c\x00h\x00\r\x00"
2021-10-04T16:10:06Z D! Grok no match found for: "\x00{\x00\r\x00"
2021-10-04T16:10:06Z D! Grok no match found for: "\x00 \x00 \x00C\x00r\x00e\x00a\x00t\x00i\x00o\x00n\x00T\x00i\x00m\x00e\x00 \x00=\x00 \x00$\x000\x001\x00D\x007\x00B\x004\x00B\x00E\x00A\x00D\x007\x002\x00E\x00B\x00C\x00F\x00\r\x00"
2021-10-04T16:10:06Z D! Grok no match found for: "\x00 \x00 \x00G\x00U\x00I\x00D\x00 \x00=\x00 \x00\\\x007\x00B\x004\x002\x00f\x005\x00b\x000\x002\x004\x00-\x002\x00a\x00d\x00c\x00-\x004\x00b\x007\x007\x00-\x009\x006\x004\x00a\x00-\x003\x00f\x001\x00a\x003\x009\x00d\x004\x008\x001\x005\x006\x00\\\x007\x00D\x00\r\x00"
[...]
when i convert the file to utf8 it can be parsed without any issues.
any idea how to solve it? the files are parsed on windows.
According to this tread grok treats utf-16 as utf-8 and is known to cause some issues. I think this is a grok issue and not a telegraf issue that can be fixed on our end.