I am recording every nap in influxdb with 3 fields:
start
stop
duration (the seconds passed between start and stop)
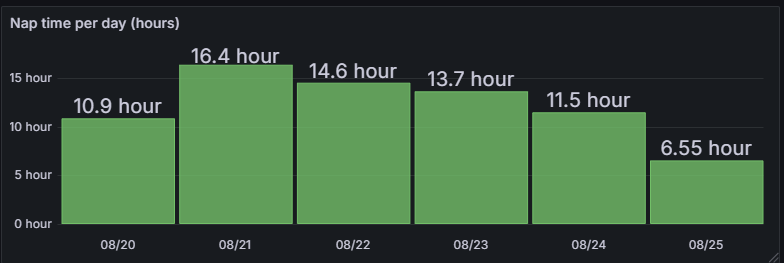
I am able to correctly group the naps per day by using the “start” field. However, everyday it happens that a sleep cycle crosses the midnight. This sleeping cycle is not correctly handled because it is recorded in the previous day instead of being split across the two days.
Here below is the script I have been using for the dashboard that does NOT handle the midnight. Would you have any suggestion about how to modify it to split the naps across midnight correctly?
Many thanks in advance!
import "math"
import "date" // Required for timezone-aware date functions
import "timezone"
option location = timezone.location(name: "Europe/Madrid")
raw = from(bucket: "baby-care")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "baby_events" and
r.event_type == "Nap" and
(r._field == "start" or r._field == "duration")
)
pivoted = raw
|> pivot(
rowKey: ["_time", "parent", "user_id", "event_type"],
columnKey: ["_field"],
valueColumn: "_value"
)
|> filter(fn: (r) => exists r.start and exists r.duration and r.start != "")
clean = pivoted
|> map(fn: (r) => ({
_time: time(v: r.start), // Must be valid ISO string
_value: float(v: r.duration), // Ensure numeric
_field: "duration",
_measurement: "baby_events"
}))
|> drop(columns: ["_start", "_stop"])
clean
|> map(fn: (r) => ({
r with
_time: date.truncate(t: r._time, unit: 1d)
}))
|> truncateTimeColumn(unit: 1d)
|> group(columns: ["_value"], mode: "except")
|> sum()
|> group(columns: ["_value", "_time"], mode: "except")
|> map(fn: (r) => ({
r with
_value: math.round(x: r._value / 3600.0 * 100.0) / 100.0 // seconds → hours
}))
|> rename(columns: { _time: "Day", _value: "Total Nap Duration (hours)" })
@borelg I understand the problem you’re trying to solve, but would you be willing to share a sample of your raw dataset? I think it’d help me to better understand how to help.
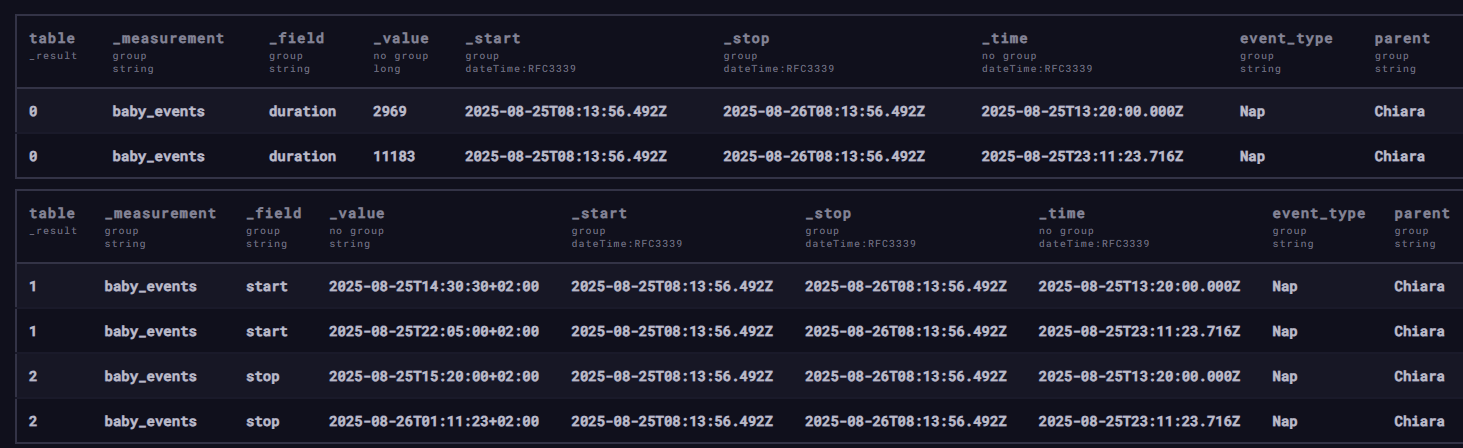
Sure, unfortunately as a new user I cannot upload attachment. Please find below an extraction of the past 24h. You might visualize them better with Excel.
Ok, this is a little hacky, but it works. It essentially transforms your nap start/stop data into state-based data (per minute). So it structures the data where each row represents a minute and the nap state during that minute. It then calculates the duration of each state each day. Note: I included the 2h offset in the last aggregateWindow() call to account for your timezone offset.