I failed to get this example sample sensor data in a sorted way via Telegraf to InfluxDB.
When doing it dircetly in InfluxDB via Task it works easily (as shown in an example):
When trying to get the same data to my bucket via Telegraf it didn’t collect the data in the correct way.
Here ist the input-section from my Telegraf.conf were I tried to get it work:
How do I need to configure the csv-options in Telegraf to receive the correct values from each of the different sensors?
Maybe somebody has a reference example on how to sort incoming data?
Unfortunately there is an error using the tag "_field " e.g.:
unable to parse ‘airSensors,_field=temperature,host=Manu,sensor_id=TLM0200 table=20i,_value=73.40202392386809 1629456570000000000’: cannot use reserved tag key “_field”
As shown in the docs: Note: Avoid using the reserved keys _field , _measurement , and time . If reserved keys are included as a tag or field key, the associated point is discarded.
However if I just delete this tag, the result is still not satisfying. What to do?
So in general tags are necessary to assign the values correctly?
After modifying the telefgam config-file with the renaming it’s working in some way.
[[inputs.http]]
urls = ["https://raw.githubusercontent.com/influxdata/influxdb2-sample-data/master/air-sensor-data/air-sensor-data-annotated.csv"]
data_format = "csv"
csv_comment = "#"
csv_header_row_count = 1
csv_skip_columns = 2 # no content in the first 2 cols
csv_tag_columns = ["_field", "sensor_id"]
csv_measurement_column = "_measurement"
csv_timestamp_column = "_time"
csv_timestamp_format = "2006-01-02T15:04:05Z07:00"
tagexclude = ["url"] # we don't need the url tag in every metric
[[processors.rename]]
[[processors.rename.replace]]
tag = "_field"
dest = "new_field"
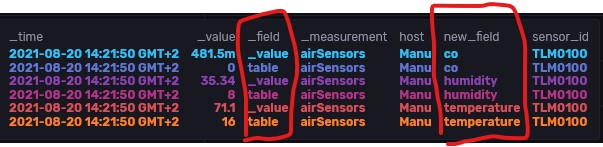
The result in InfluxDB is that the data is now shown separatet for “new_field” including co/humidity/temperature as desired.
But there ist still the “_field” which splits in _value for the sensor values and the table number.
As you can see here in this example data for 1 sensor in InfluxDB:
Thanks for your support. For now this works.
I just don’t fully understand the logic at the moment.