Hello community,
we have written a software, that’s supposed to migrate time series data into influxdb.
The size of the dataset that we want to migrate is about 2 billion entries in total spanning across approx. 130k series.
What our migration software does againt influxdb is basicly querying against some not (yet) existing series (getting emtpy results) and sending data time-series wise. So after data is imported it is actually not touched anymore during this phase.
While this is running, we observe a constantly increasing memory consumtion of the influxd process as shown here:
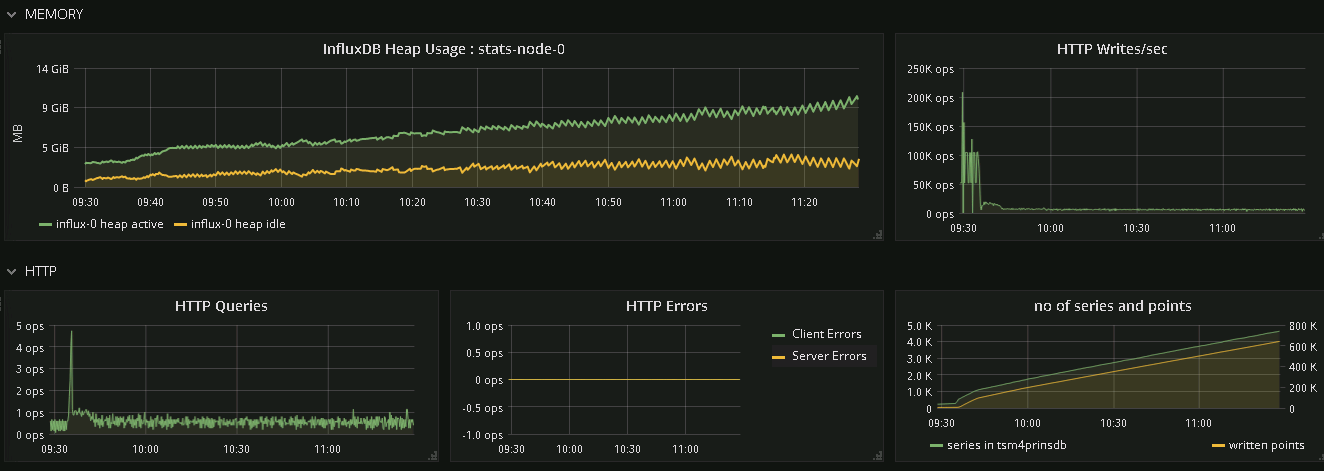
My questions are the following:
- Why keeps memory usage increasing?
- What can we do to influence this - either by changing settings of influxdb.config or by changing the behaviour of our migration-code?
- What’s your expectation of memory consumtion importing data of the size mentioned above?
Thanks for your help and comments,
Lars
