Hi, I am running Telegraf & InfluxDB as docker containers deployed over two separate ec2 instance in the same subnet, the type of instance is r5.large and r5a.4xlarge respectively. The input which I am using is Kafka, the frequency of data is every 5 minutes. I am running two Telegraf containers for two different Kafka Brokers. For one Telegraf, I am using 7 kafka topics and for others its 25/26 topics.
For the second Telegraf, I am getting a “Context Deadline exceeded error”, however after restarting every thing works fine until the next time. I want to know, what might be the issue and how to debug that. I am using http timeout as “15s”. I will be shifting the topics to another telegraf, however before that, I would wanted to see some logs on the basis of which “Context Deadline” message is coming.
On Telegraf - we are using quite heavy processing but the code itself is most optimized according to our use case. Below are the processor plugin configurations -
Starlark processor - Extract 3 different metrics from each metric
Convertor - Converting data type of field from string to float
Adding some new tags based on regular expression.
I am using jitter as well to make sure both Telegraf’s are not pushing data to influxDB at same time.
This is generally due to a connection to your input having issues. It could be DNS, it could be network blips, it could be disconnects, a proxy, etc.
what might be the issue and how to debug
Telegraf’s handling of Kafka connections is all done by sarama. There is no way for us to give insight without the sarama logs. You need to run telegraf with --debug enabled and see what sarama is reporting.
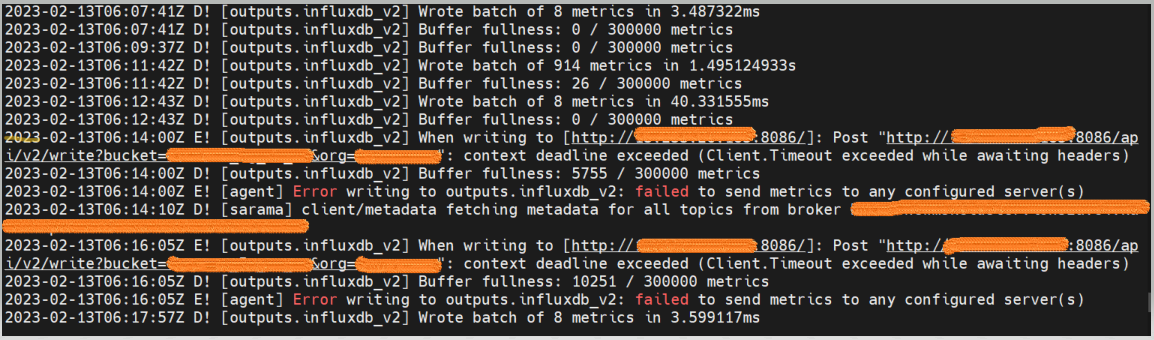
2023-02-13T06:14:00Z E! [outputs.influxdb_v2] When writing to [http://influxdb_url:8086/]: Post "http://influxdb_url:8086/api/v2/write?bucket=bucket_name&org=org_name": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
2023-02-13T06:14:00Z D! [outputs.influxdb_v2] Buffer fullness: 5755 / 300000 metrics
2023-02-13T06:14:00Z E! [agent] Error writing to outputs.influxdb_v2: failed to send metrics to any configured server(s)
So, until I did not restarted the container, we kept seeing the same error. The duration was for about 24 hours. After restarting container, everything is working fine since last 12 hours now.
Ah from influxdb output not kafka. My comment above, about this usually being related to networking issues still stands though. I am surprised to see this if they are on the same subnet, are they in the same availability zone?
Yes, same availability zone. For InfluxDB, we are running some 100-110 tasks which are separated by 30s/10s offset, in total taking 40-45 to calculate, apart from that load on influxdb is not much.