i have 2 time series which return Workorder IDs.
The same IDs do not have the same timestamp within the two time series.
Also only a few IDs from the first time series can be found in the second.
Is there a way to compare the values in the two columns and post only those which cannot be found in both time series?
I tried using a conditional mapping function like this:
The difference between our usecases is, that i have the data stored in 2 measurements.
I have to create 2 seperate tables and use the union() function before I can use the map() function. Can this be the problem?
@Jay_Clifford : Your example of comparing two CPU cores is very close to my query, where I wish to compare setpoint vs actual. However, I get the following error, despite that my query syntax generally mirrors yours. Any idea why mine won’t work?
Can you show me the output of your table after the pivot (remove the map function for now)? I want to see what the raw tables look like and the data types they hold. Many thanks
As my first assumption based upon your query is that you are trying to compare two values that actually where tags:
r["MeasType"] == "actual" #filtering for tag
r["_field"] == "actual" #filtering for field
This means the less than expression is invalid as you are trying to compare two string values (since they are tags). You do have a few options:
Prepare your data so actual and setpoint come in as fields. This would be the easiest option though I am not sure what your data ingest process looks like.
wrap your r.actual and r.setpoint in a int() transformer. This should convert your string values to numerical values for processing
I am still in the planning / testing phases of using Flux and can also change the data ingestion process according to what makes sense. And you are correct, I am trying to compare two tags (setpoint and actual). But having watched & read all of the info / webinars on data schema, I believe that when I ingest two values at the same time (setpoint: 1580, actual: 1577), and I assign each a MeasType tag as setpoint or actual, then my data is more compact and I can then perform operations comparing these two values.
So I can indeed change the data ingest and have the actual & setpoint (which are being ‘grabbed’ at the same instant) come in as two fields, but I presumed that was not the right approach.
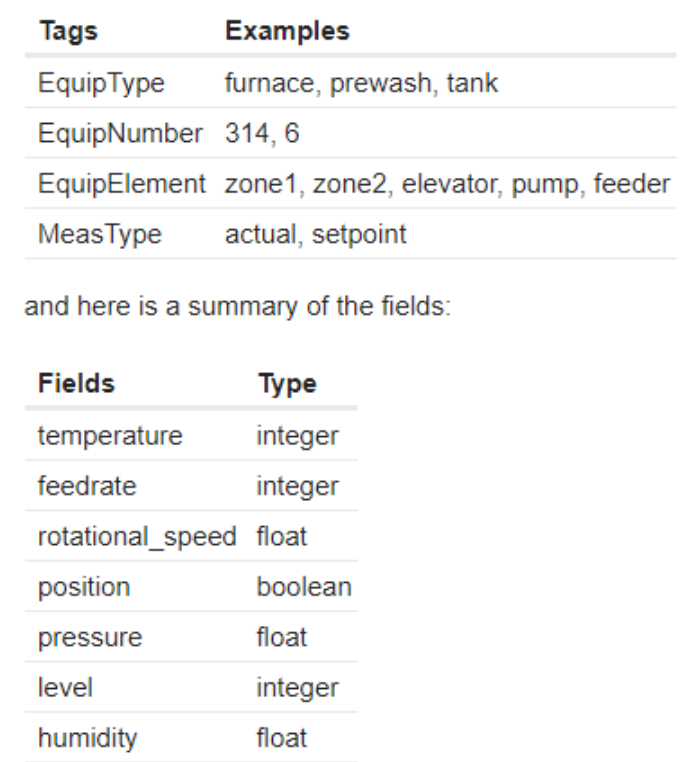
PS: Here is a list of my tags and fields. If I make then proposed change of ingesting actual & setpoint, then the list of fields would double to temperature_setpoint, temperature_actual, feedrate_setpoint, feedrate_actual, rotational_speed_setpoint, rotational_speed_actual, etc. This is what seemed unnecessarily complex to me, so I created the MeasType field.
@grant1 sorry this makes alot more sense and you are correct to use actual and setpoint as tags like you intended. My confusion came from the fact that you were trying to compare the values of two tags i.e
setpoint = "1000" < actual = "500"
What you have done makes sense but sadly your query won’t based on the pivot you have created. Lets look a smaller example:
In this case, I have a temperature field with the tags either: actual or setpoint. We pivot on the tag column MeasType rather than the field key. This will provide us with the two columns for comparison like so:
Note: you must include 1 field to compare which belong to the value column. The above will not work if you try comparing more than field (temperature, pressure) etc.
@Jay_Clifford I pivoted on the tag column MeasType and I can indeed now perform conditional math on the setpoint vs. the actual. Thank you for explaining.
One last question: How can one get the absolute value of the difference between setpoint and actual? The map function below works, but when I try to enter math.abs I get syntax errors.
@Jay_Clifford Returning to the pivot and conditional arguments about a month ago, how would one adjust the above query so that only the absolute difference of setpoint - actual is returned?
I need to use this in a Grafana alert, and if I can get the query to only return the absolute difference, then I should be good to go.
but I get the values for actual, difference, and setpoint: (remember that I want only the difference)
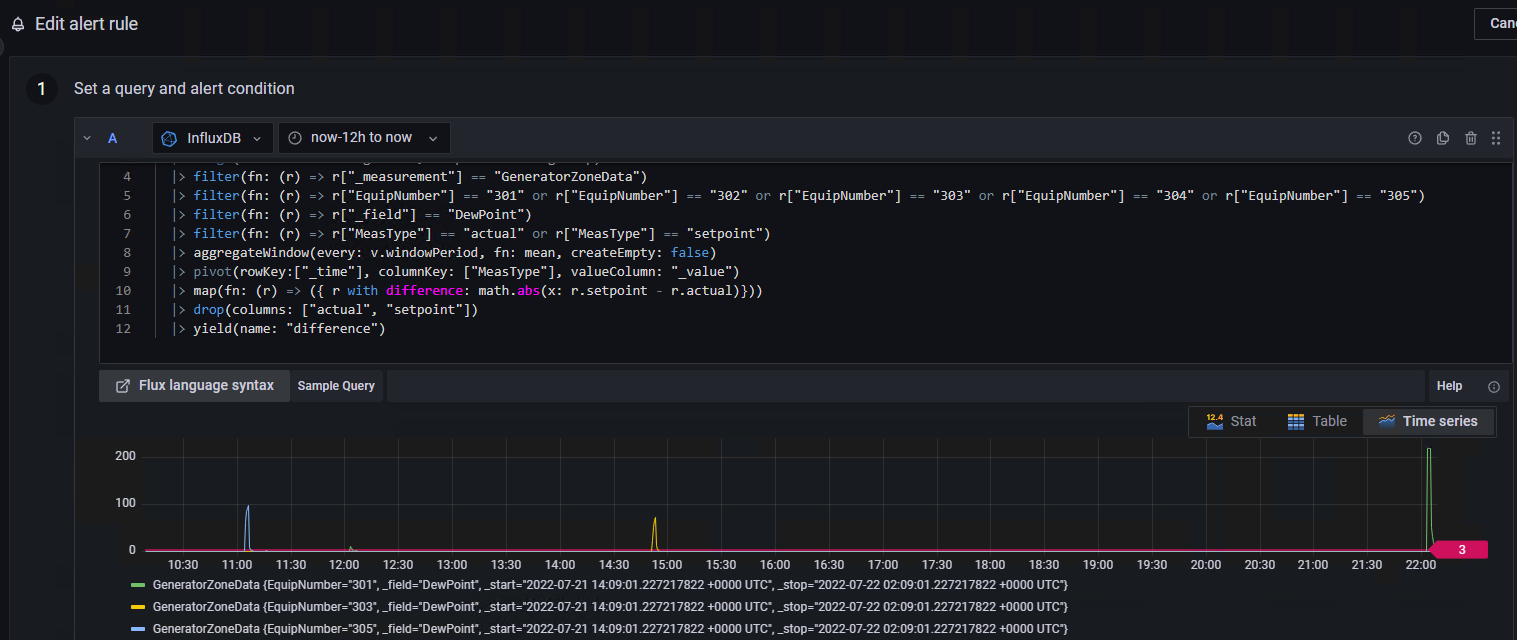
In Grafana (where I am trying to write the same query for an alert), it is displaying actual and setpoint (the blue and green lines) and then the difference (the yellow line). I want only the yellow line (values) to use in the query.
where it does not seem to like whenever there is a large difference value (it can be ~250 or so every 12 hours). On a small time window, Grafana does NOT throw an error whenever the difference is small (and apparently when there are no floats calculated).
@Jay_Clifford and all: No further action required. This query is solid and works great in InfluxDB. Sometimes these same queries go haywire in Grafana, and the solutions are elusive. I think the error it was displaying was somehow related to spanning a larger time window, and then some value in that window returned an error. Again, it works fine in InfluxDB.
Here is a slight variation of the same query with a now-12h to now time window and no errors:








 . Just drop me a message if you need anymore help
. Just drop me a message if you need anymore help