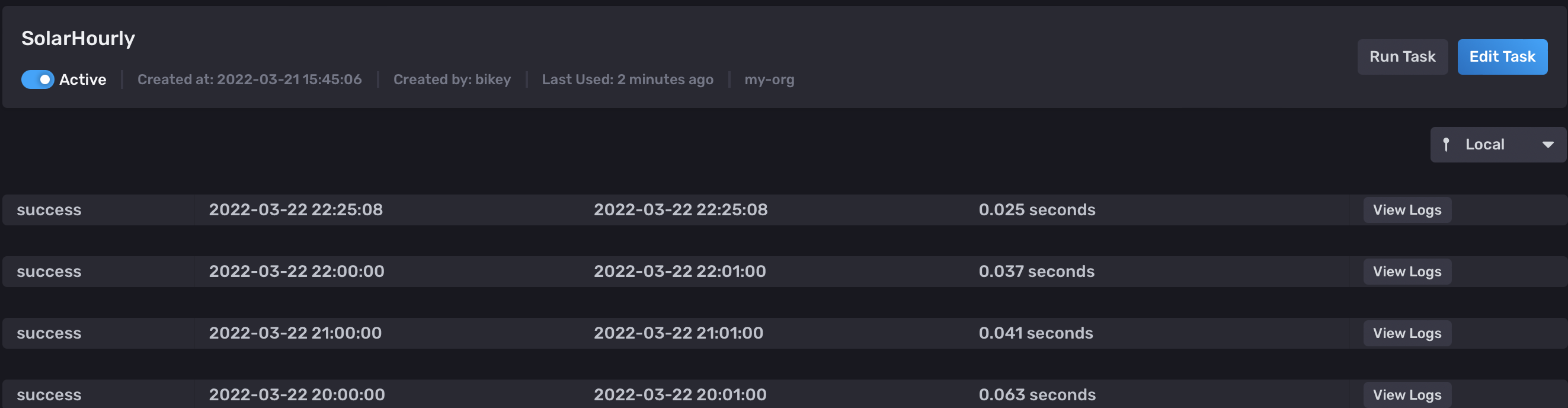
Hi,
I’m a newbie, moving from InfluxDb 1.8 to 2.x. So I have to migrate my continuous queries to tasks.
Now I have made up a Flux Task that nicely downsamples my data to hourly or daily level, and writes this to the appropriate bucket.
This works all fine when I start the task by pressing the “Run Task” button in the GUI but not when the task runs according to the schedule. The log show " success" at the scheduled times, so it is run at the appropriate times, but I see no data appearing in the target bucket.
This is the task:
option task = {
name: "Solar_Hourly",
every: 1h,
offset: 5m,
}
from(bucket: "telegraf")
|> range(start: -task.every)
|> filter(fn: (r) => r["measurement"] == "solar")
|> filter(fn: (r) => r["topic"] == "import")
|> aggregateWindow(every: 1h, fn: last, createEmpty: false)
|> difference(
nonNegative: true,
columns: ["_value"],
keepFirst: false,
)
|> map(
fn: (r) => ({
_value: r._value,
_time: r._time,
_measurement: "solar_hourly",
_field: "usage",
}),
)
|> to(
bucket: "meters_hourly",
org: "my-org",
)
In the Influx logs I see no errors or anything that helps me to pinpoint why this doe not work.
Anybody a clue what could be the issue?