Hello everyone,
I’m new to the Influx world. I’ve been saving my values from the PV system for a few days now and visualizing them in Grafana. I have managed the simple things well. But now I’m reaching my limits.
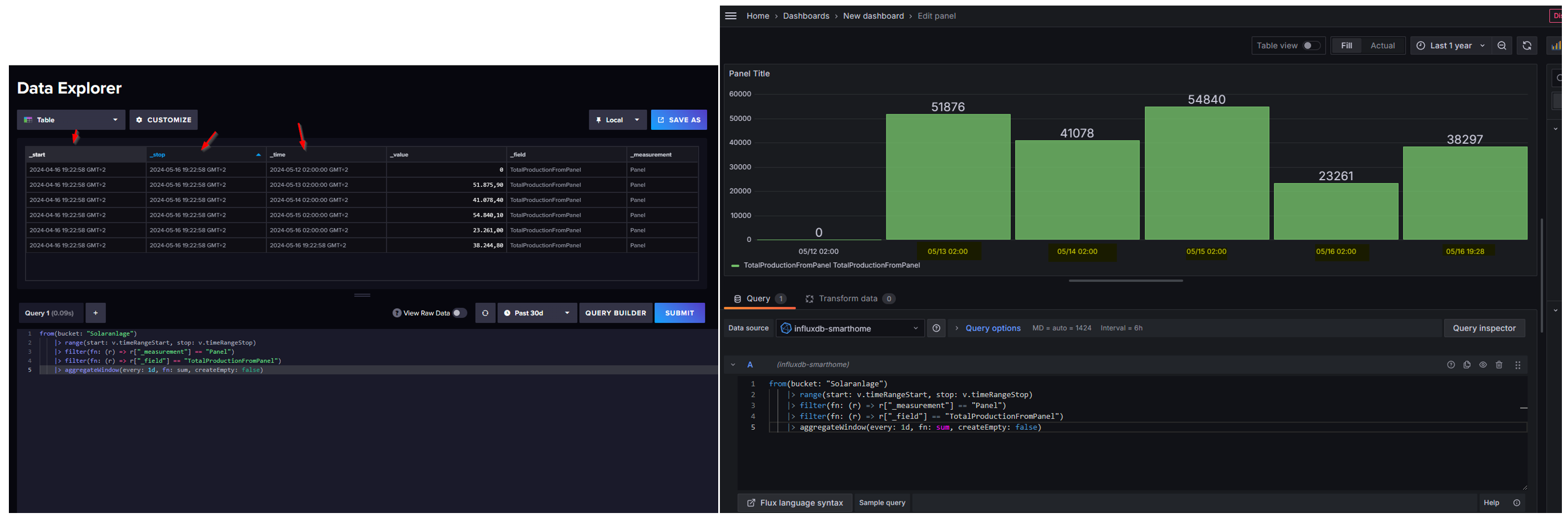
For example, I would like to visualize how much I have generated per day, week, month or year.
The data for this is written to the influx every 3 seconds in kilowatts.
I use this fluxquery to visualize a normal graph of the values.
@Nicolas_Lauinger You just need to change the every and fn parameters in the aggregateWindow function. every defines the window interval used to downsample data. fn defines the aggregate or selector function to apply to each window. So for a daily total, it would be:
If you wanted, you could take it a step further and define a custom variable in Grafana that would allow you to select from a list of window durations. Let’s call the variable per with the following variable definition:
Day : 1d,Week : 1w,Month : 1mo,Year : 1y
Because variable values are inserted as strings, you’ll need to cast the string duration to an actual duration type using the variable. It would look something like this:
Thanks @scott for the feedback.
What I don’t really understand is what the columns _start _stop _time stand for. Is _start and _stop the v.timeRangeStart and v.timeRangeStop?
Can I somehow format the result in influx with a pivot function or something. Because the desired result for day would always be just the date. If I just take the query for now, it looks like this in Grafana.
And I don’t think simply calculating the sum gives the right result. The figures are far too high for daily production. Would it be necessary to divide the results by 1000?
The _start and _stop columns are added by the range() function and initially represent the time bounds of the query. However, when ever you perform a windowing operation, the _start and _stop columns are updated to represent boundaries of each window. You then get tables grouped by those columns, so all rows that fall in the same window are grouped in the same table.
In your actual results, you don’t need these columns, but they are important at certain stages of your query. If you want, you can use drop() to drop them at the end of your query:
// ...
|> drop(columns: ["_start", "_stop"])
Grafana handles the rendering of the bar labels. It looks for the first string or time columns. In this case, it’s using time. To use a custom format, you’ll have to map in a new column with a formatted date. I’d recommend creating a custom function to render a date strings and use map() to apply to function to each row’s _time value and store in a new column.
So with the suggestion above, and this one, your query would look like: