I’ve found an issue in managing cumulative data, meaning counters that only increment and sometimes reset (usually due to a restart).
I always had performance issues while querying those data, therefore I’ve decided to aggregate them and turn them into snapshot data using a Continuous Query, which works (almost) perfectly… almost because it loses data.
With performance issue I mean that using pre-aggregate data takes 74ms, while using the raw cumulative counters may take over 6s
The data
The data are about IO usage, 100% cumulative counters, with 9 tags and 6 fields (it doesn’t matter logically), sampled every 15 seconds.
Sample Data
time,company,database_name,file_type,host,logical_filename,measurement_db_type,physical_filename,read_bytes,read_latency_ms,reads,rg_read_stall_ms,rg_write_stall_ms,sql_instance,volume_mount_point,write_bytes,write_latency_ms,writes
25/08/2022 12:27:01,quantumdatis_demo,AdventureWorks2016,LOG,QDSRVMONITOR,AdventureWorks2016_Log,SQLServer,F:\MSSQL14.SQL2017\MSSQL\DATA\AdventureWorks2016_Log.ldf,4554805248,204589,71212,0,0,SQLCSRV04:SQL2017,F:,20368084992,641401,356320
25/08/2022 12:28:01,quantumdatis_demo,AdventureWorks2016,LOG,QDSRVMONITOR,AdventureWorks2016_Log,SQLServer,F:\MSSQL14.SQL2017\MSSQL\DATA\AdventureWorks2016_Log.ldf,4562132992,204898,71325,0,0,SQLCSRV04:SQL2017,F:,20412518400,642159,357105
25/08/2022 12:29:00,quantumdatis_demo,AdventureWorks2016,LOG,QDSRVMONITOR,AdventureWorks2016_Log,SQLServer,F:\MSSQL14.SQL2017\MSSQL\DATA\AdventureWorks2016_Log.ldf,4562132992,204898,71325,0,0,SQLCSRV04:SQL2017,F:,20412518400,642159,357105
25/08/2022 12:30:00,quantumdatis_demo,AdventureWorks2016,LOG,QDSRVMONITOR,AdventureWorks2016_Log,SQLServer,F:\MSSQL14.SQL2017\MSSQL\DATA\AdventureWorks2016_Log.ldf,4562132992,204898,71325,0,0,SQLCSRV04:SQL2017,F:,20412518400,642159,357105
25/08/2022 12:31:01,quantumdatis_demo,AdventureWorks2016,LOG,QDSRVMONITOR,AdventureWorks2016_Log,SQLServer,F:\MSSQL14.SQL2017\MSSQL\DATA\AdventureWorks2016_Log.ldf,4562132992,204898,71325,0,0,SQLCSRV04:SQL2017,F:,20412518400,642159,357105
25/08/2022 12:32:01,quantumdatis_demo,AdventureWorks2016,LOG,QDSRVMONITOR,AdventureWorks2016_Log,SQLServer,F:\MSSQL14.SQL2017\MSSQL\DATA\AdventureWorks2016_Log.ldf,4562132992,204898,71325,0,0,SQLCSRV04:SQL2017,F:,20412518400,642159,357105
25/08/2022 12:33:00,quantumdatis_demo,AdventureWorks2016,LOG,QDSRVMONITOR,AdventureWorks2016_Log,SQLServer,F:\MSSQL14.SQL2017\MSSQL\DATA\AdventureWorks2016_Log.ldf,4562132992,204898,71325,0,0,SQLCSRV04:SQL2017,F:,20412518400,642159,357105
25/08/2022 12:34:01,quantumdatis_demo,AdventureWorks2016,LOG,QDSRVMONITOR,AdventureWorks2016_Log,SQLServer,F:\MSSQL14.SQL2017\MSSQL\DATA\AdventureWorks2016_Log.ldf,4562132992,204898,71325,0,0,SQLCSRV04:SQL2017,F:,20412518400,642159,357105
25/08/2022 12:35:01,quantumdatis_demo,AdventureWorks2016,LOG,QDSRVMONITOR,AdventureWorks2016_Log,SQLServer,F:\MSSQL14.SQL2017\MSSQL\DATA\AdventureWorks2016_Log.ldf,4562132992,204898,71325,0,0,SQLCSRV04:SQL2017,F:,20412518400,642159,357105
Queries
Here is the query used to turn the data from cumulative to snapshot (as concise as possible)
SELECT
non_negative_difference(last(read_bytes)) AS read_bytes
FROM temp.sqlserver_database_io
WHERE
time > now() -5m
GROUP BY
TIME(1m)
,*
The issue with this query is that the group intervals are not inclusive on both sides of the range, which translates to losing data given this is a cumulative counter.
Given the following chart:

What happens when grouping by 1m is that part of the data is unused/lost, as the time buckets created will be from hh:mm:00.0000 to hh:mm:59.9999, visual representation below
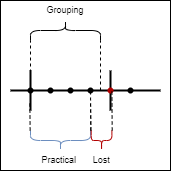
in my case this means that the difference (between last and first) is computed on the following sets.
00:00:00 | interval 1
00:00:15 | interval 1
00:00:30 | interval 1
00:00:45 | interval 1
00:01:00 | interval 2 --this should be both, end of int 1 and beginning of int 2
00:01:15 | interval 2
00:01:30 | interval 2
In order to solve this, I came up with the following query, in which the difference calculation is performed point by point (therefore no data is lost), and is later aggregated in 1m intervals.
The problem is that it takes 2-3x more time that the previous query.
SELECT
sum("reads") as "reads"
FROM (
SELECT
non_negative_difference("reads") as "reads"
FROM "$InfluxDB_RetentionPolicy"."sqlserver_database_io_cumulative"
WHERE
time > now() -5m
GROUP BY *
)
GROUP BY
*
,time(1m)
Questions
- Is there a way of having inclusive grouping intervals? (I think not)
- How can this kind of issue be solved? are there other approaches I’m missing?
